-
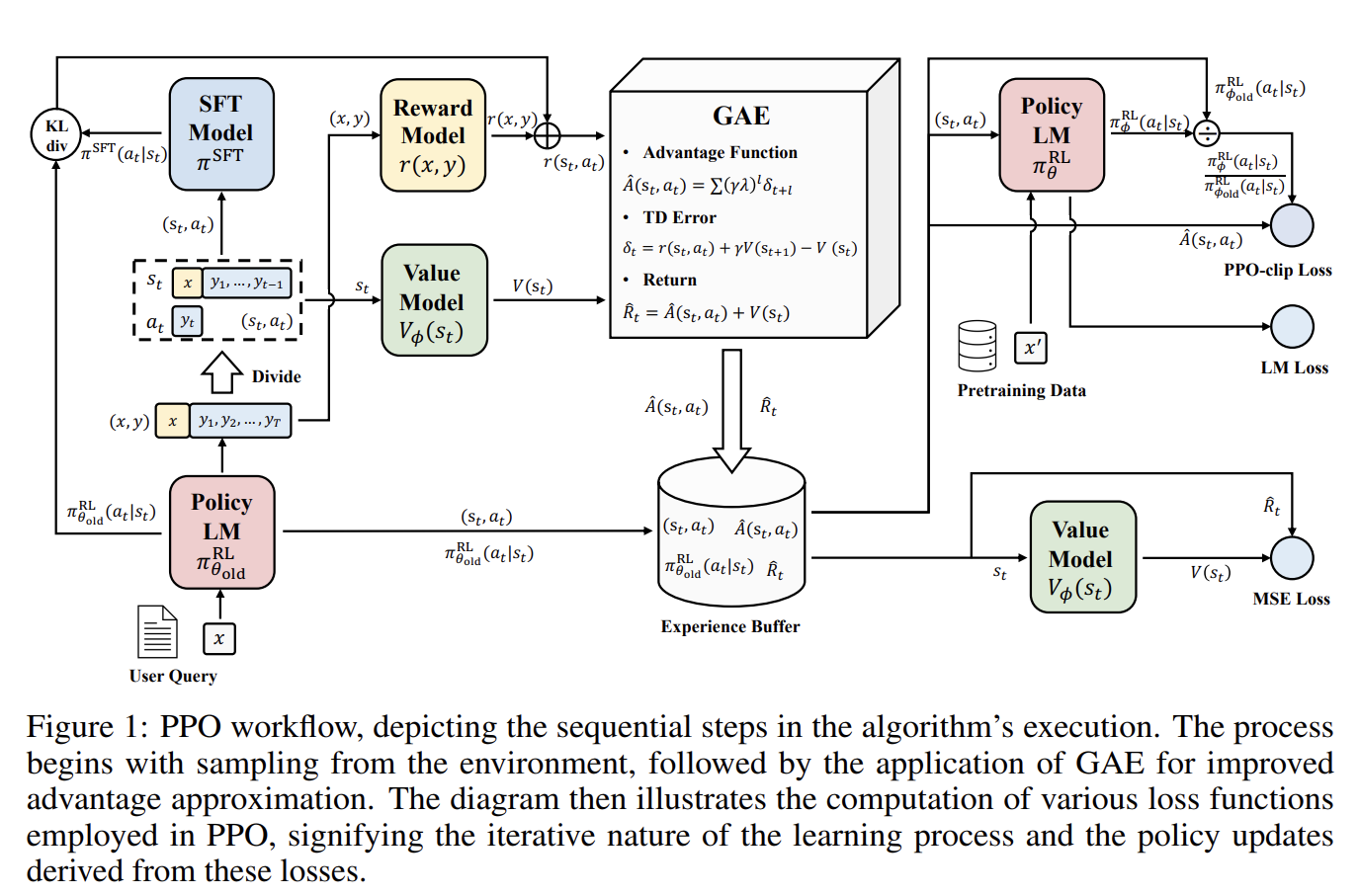
Learning RLHF (PPO) with codes (Huggingface TRL)
Tech essays of Reinforcement Learning from Human Feedback (RLHF) and Proximal Policy Optimization (PPO) with codes in Huggingface TRL.
-
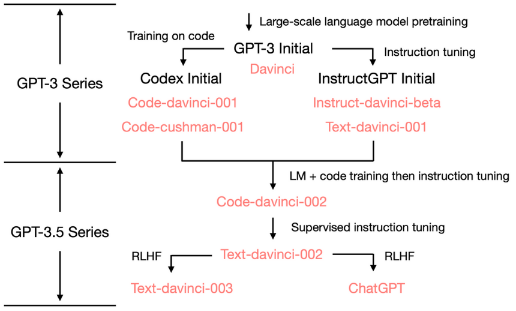
Reading Notes of How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources
Reading notes of Yao's notes of "How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources".
-
Huggingface parallel training for solving the CUDA out of memory issue
Document a workable solution for the annoying CUDA Out Of Memory (OOM).

-
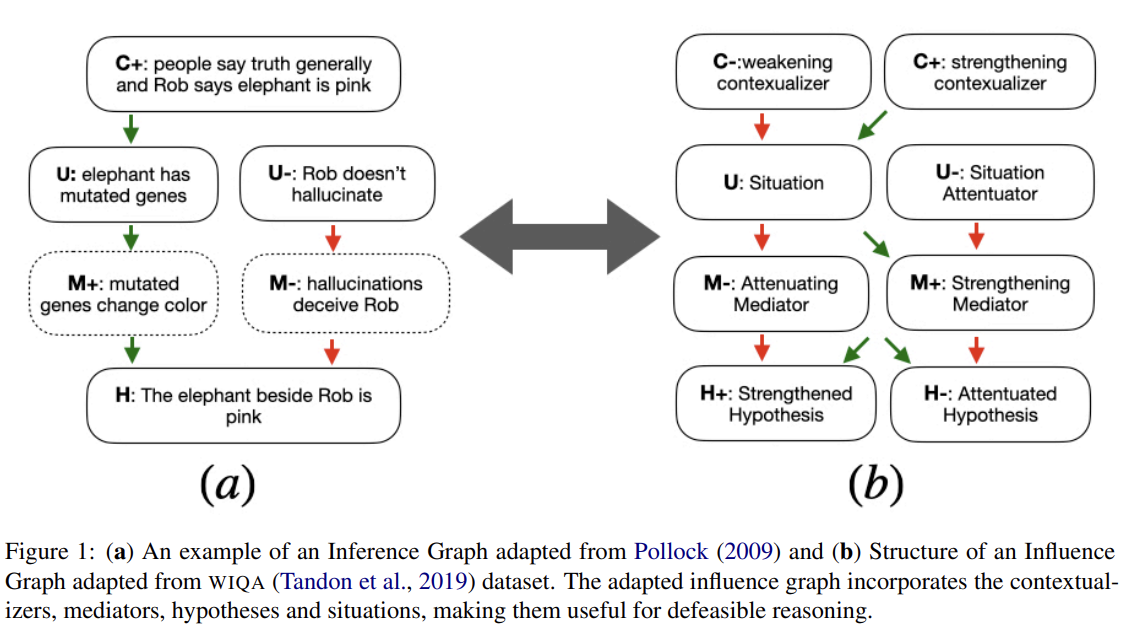
Could you give me a hint? Generating inference graphs for defeasible reasoning
A reading note about a paper related to defeasible reasoning.