Learning RLHF (PPO) with codes (Huggingface TRL)
I briefly learned PPO in the RL and Modern NLP, but I didn’t quite grasp it, so over the past couple of days, I glanced at the source code implementation on TRL - Transformer Reinforcement Learning (huggingface.co) and the paper [2307.04964] Secrets of RLHF in Large Language Models Part I: PPO (arxiv.org). I feel much clearer about it now. (Seems like there are quite a few errors in the paper…
First, let’s go over the PPO workflow:
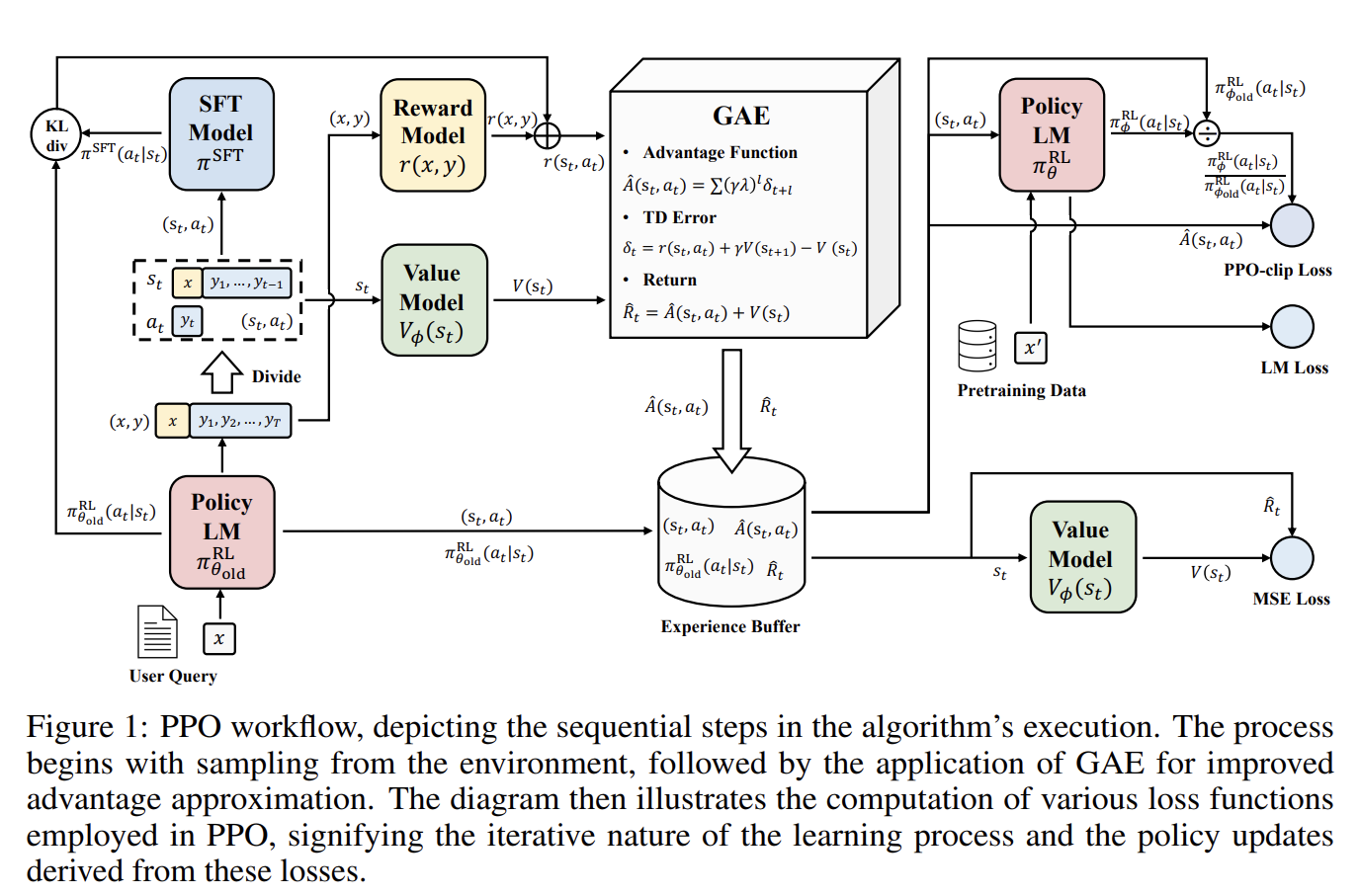
We start with an initial state where we have an SFT Model and its “clone brother”, the RL Model, both referred to as policies. There’s also a Value Model. In PPO, there’s a process called GAE, which requires the use of Advantage, TD-Error, and Return. Then, finally, through these calculated elements, we derive the PPO-clip Loss, LM Loss, and MSE Loss.
RL Prerequisites
Policy Gradient
The core objective of RL is to optimize the RL Model (\(\pi_{\theta}^{\text{RL}}\)). Based on the Policy Gradient and the Log-likelihood Trick, our goal is to maximize the Return under the RL policy (which can initially be understood as Reward; it’s actually a multi-time step total discounted reward), using Gradient Ascent:

Calculating this through Monte-Carlo Sampling leads to high variance, so subtracting the baseline is a better approach. In RL courses, it’s known that the baseline is generally the expected reward, which is the V-Value.
Here, I’m not sure why the second and third \(\Phi_{t}\) are not the total discounted reward.
Advantage, V-Value, and Q-Value
It was my first time learning about the relationship between Advantage and Q-Value. After deriving from the Bellman equation for one step, it appears to be correct indeed. I’ve always learned in class that \(A_{t}=r_{t}+\gamma V(s_{t+1})-V(s_{t})\):
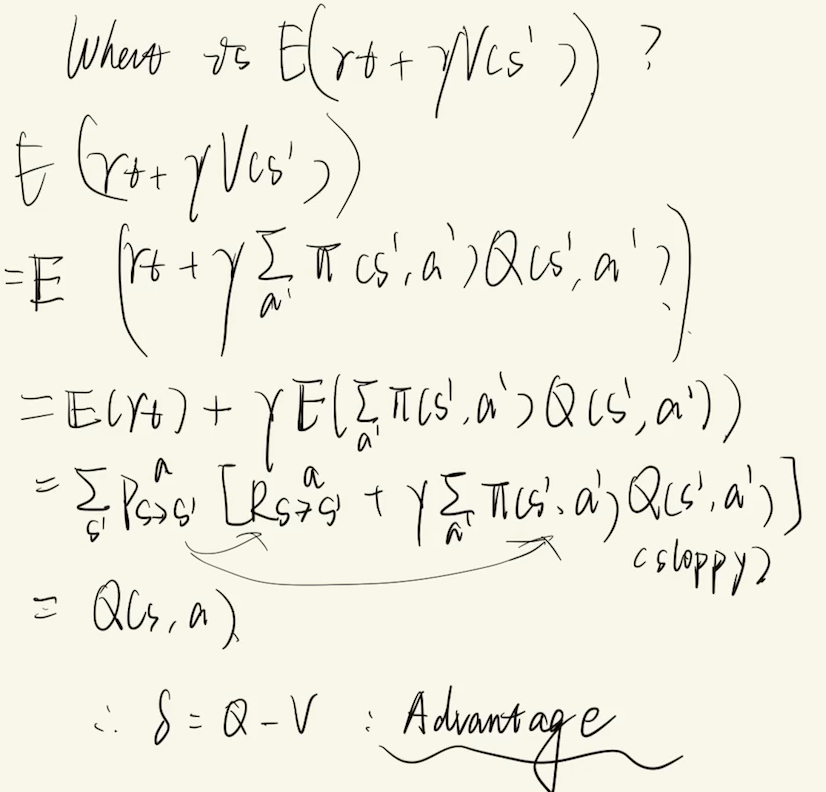
A2C (Advantage Actor-Critic)
According to Policy Gradient, we can train both a policy model and a value model. The value model should be as close as possible to the total discounted reward (return), hence the use of MSE loss, while the policy model should aim to maximize the return, hence equation (5) is used:

Generalized Advantage Estimation
For multi-time step advantage calculation, see here:

With a small \(k\), the bias is large. With a large \(k\), the variance is large. A trade-off is needed, leading to the use of GAE:
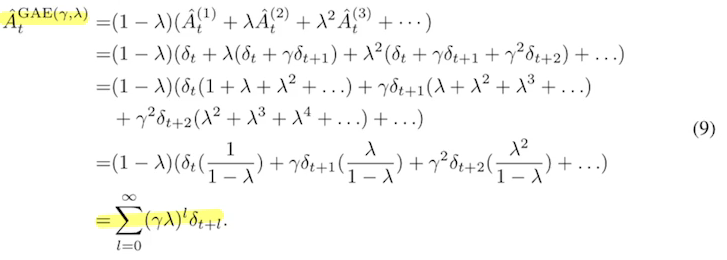

This can be simplified into a loop using the algorithm by Qin Jiushao:
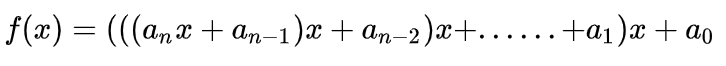

This is how it’s implemented in the TRL code.
PPO improves upon the A2C foundation.
RLHF-PPO
PPO adds constraints on top of A2C to prevent too significant updates in the policy model, ensuring the updated policy model “does not deviate too much” from the previous. The principles have been discussed in RL courses, with lengthy proof formulas, hence not listed here.
Reward
This is part of the training process. The RLHF’s Reward Function is pre-trained:

In PPO, total reward is calculated as follows:

Note: The KL here and the KL in the later Update Policy section are not exactly the same. Here, KL is calculated between the old policy before each Update Policy and the original SFT model, whereas later, KL is calculated between the policy before and after the update! In the code, the reward is added to the action of generating the last token, with the rest being 0, adhering to the principle of sparsity.
Update Policy:
TRPO

PPO-CLIP

It’s essentially a one-way clip, preventing the model from trying too hard in a good/bad direction when the action is good/bad. Detailed explanation:
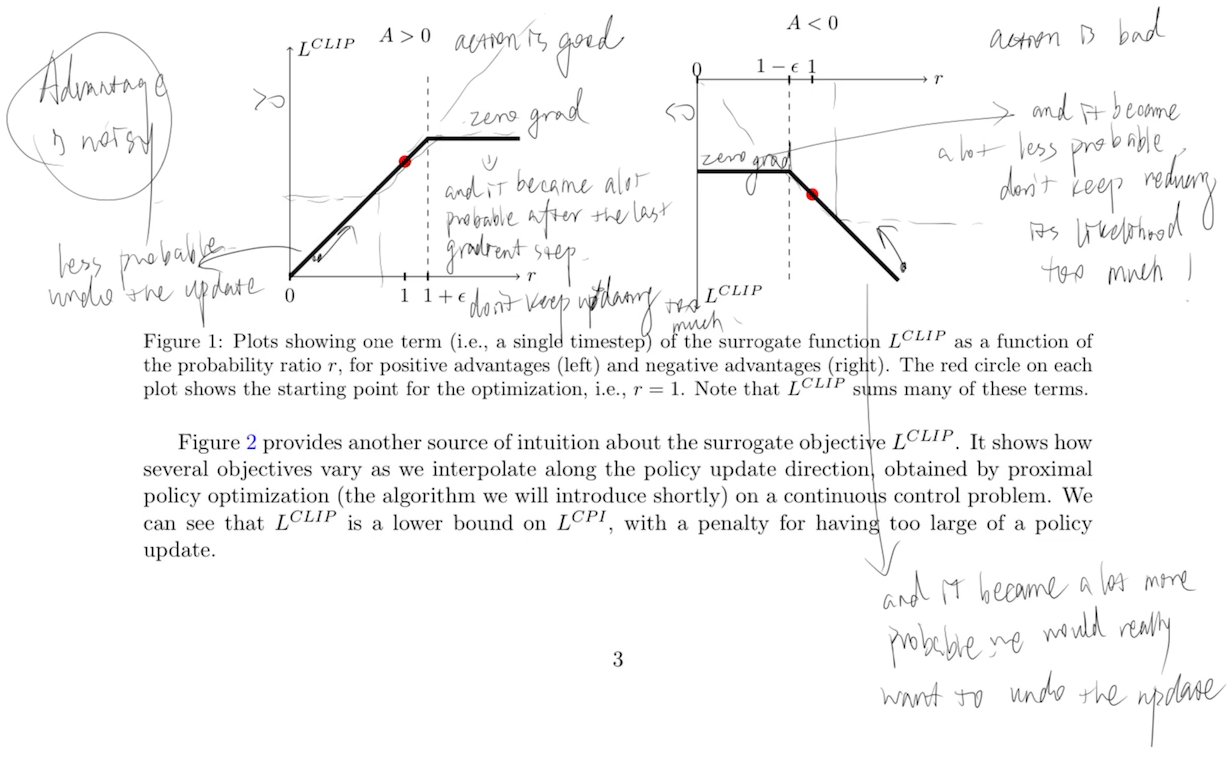
Update Value
The code also clips the value, then takes the max loss, which is somewhat unusual:

Mixing Pretraining Gradients
This part was done by InstructGPT and seems not to be implemented in TRL. It corresponds to the LM loss in the workflow:

Pseudocode
The pseudocode and A2C differ slightly from the workflow diagram; in TRL, I did not observe an experience buffer/sampling:

Code Implementation
Overall
When using, simply call the ppo_trainer.step() function. This function’s internal structure is detailed in the TRL GitHub repository:
trl/trl/trainer/ppo_trainer.py at v0.7.1 · huggingface/trl (github.com)
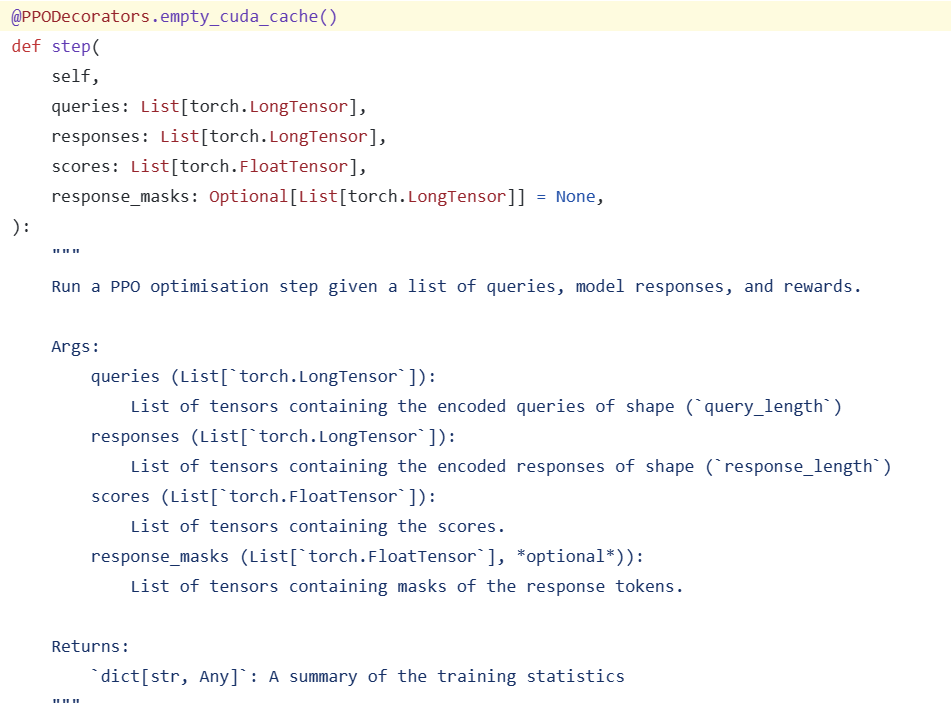
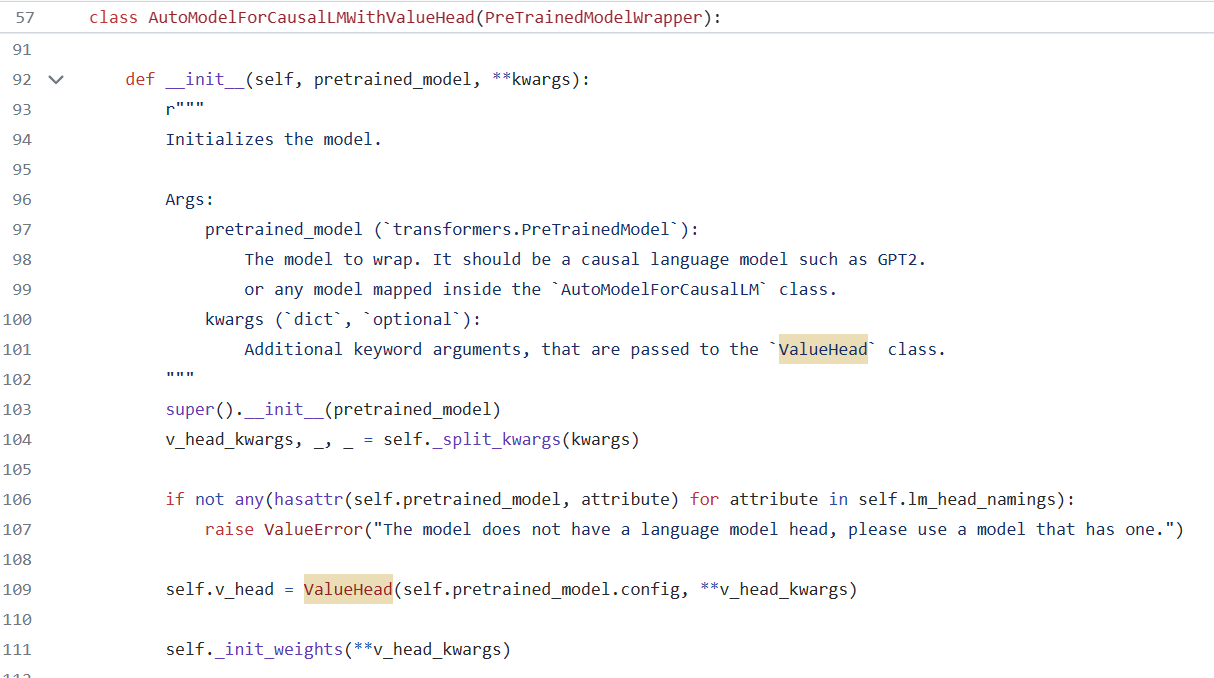
Upon creating the trainer, you must pass in an SFT model. The trainer clones it into a reference model (an unupdated SFT) and a policy model, either AutoModelForCausalLMWithValueHead or AutoModelForSeq2SeqLMWithValueHead. This Value Head acts as the Value Model.
Before entering the step, query and response embeddings are fed in batches, along with the reward for the response. You need to:
for batch in ppo_trainer.dataloader:
query_tensors = get_query_tensors()
response_tensors = generate_response_tensors_given_query_with_policy_LM()
rewards = get_reward_score_for_the_response()
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
Inside the step function, the process begins with two significant operations around lines 665 and 680:
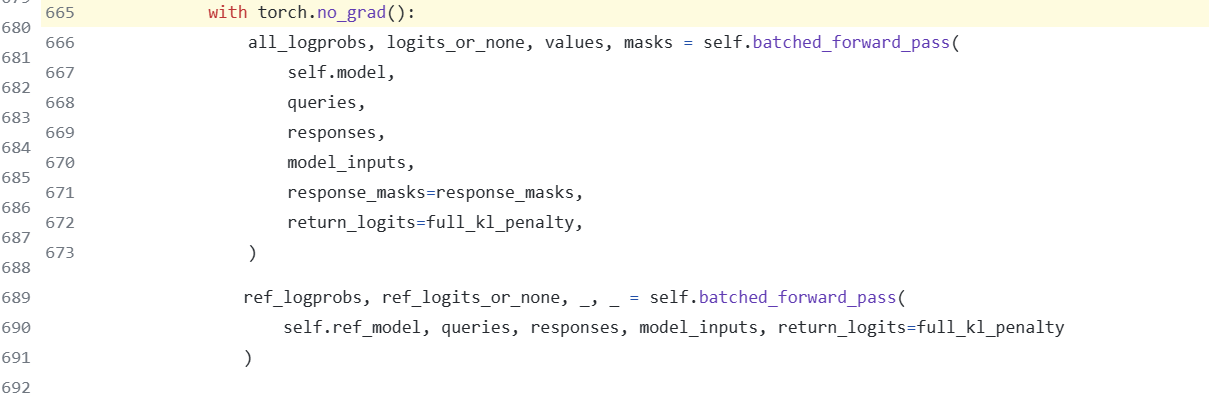
These operations involve model forward passes and reward computations, as highlighted below:
How to Do Model Forward
The batched_forward_pass() function calculates the RL model’s policy probabilities \(\pi_{\theta_{\text{old}}}^{\text{RL}}(y_{w}\vert x)\) (all_logprobs), the SFT model’s policy probabilities \(\pi^{\text{SFT}}(y_{w}\vert x)\) (ref_logprobs), and the values \(V(x)\) (values).
trl/trl/trainer/ppo_trainer.py at v0.7.1 · huggingface/trl (github.com)


The logprobs function calculates the probabilities based on the logits, which represent the scores for all tokens in the vocabulary at each position in the sequence. After applying softmax, the probabilities of the tokens appearing in the response are determined. The comparison involves decoder input from index 1 and decoder output from 0 to the second-to-last token.
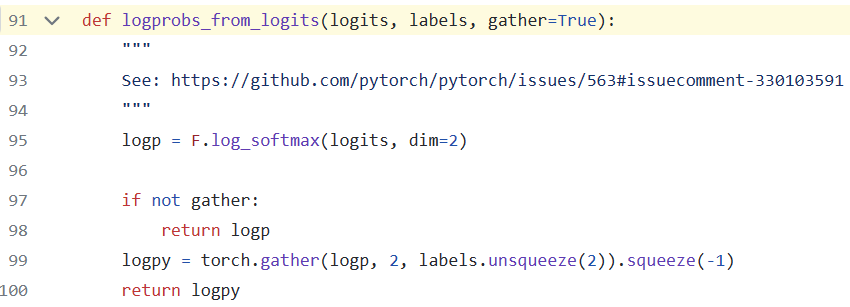
Additionally, a mask (Line 959) is applied to ignore the first token and calculate values only for tokens from index 1 to before the padding token.
In Line 946, logits, _, values = model(**input_kwargs), what is the meaning of values here? Does the forward function in the HuggingFace have this return value? It turns out that TRL uses LMWithValueHead here, letting the model have a value_head attribute, which is a linear layer.
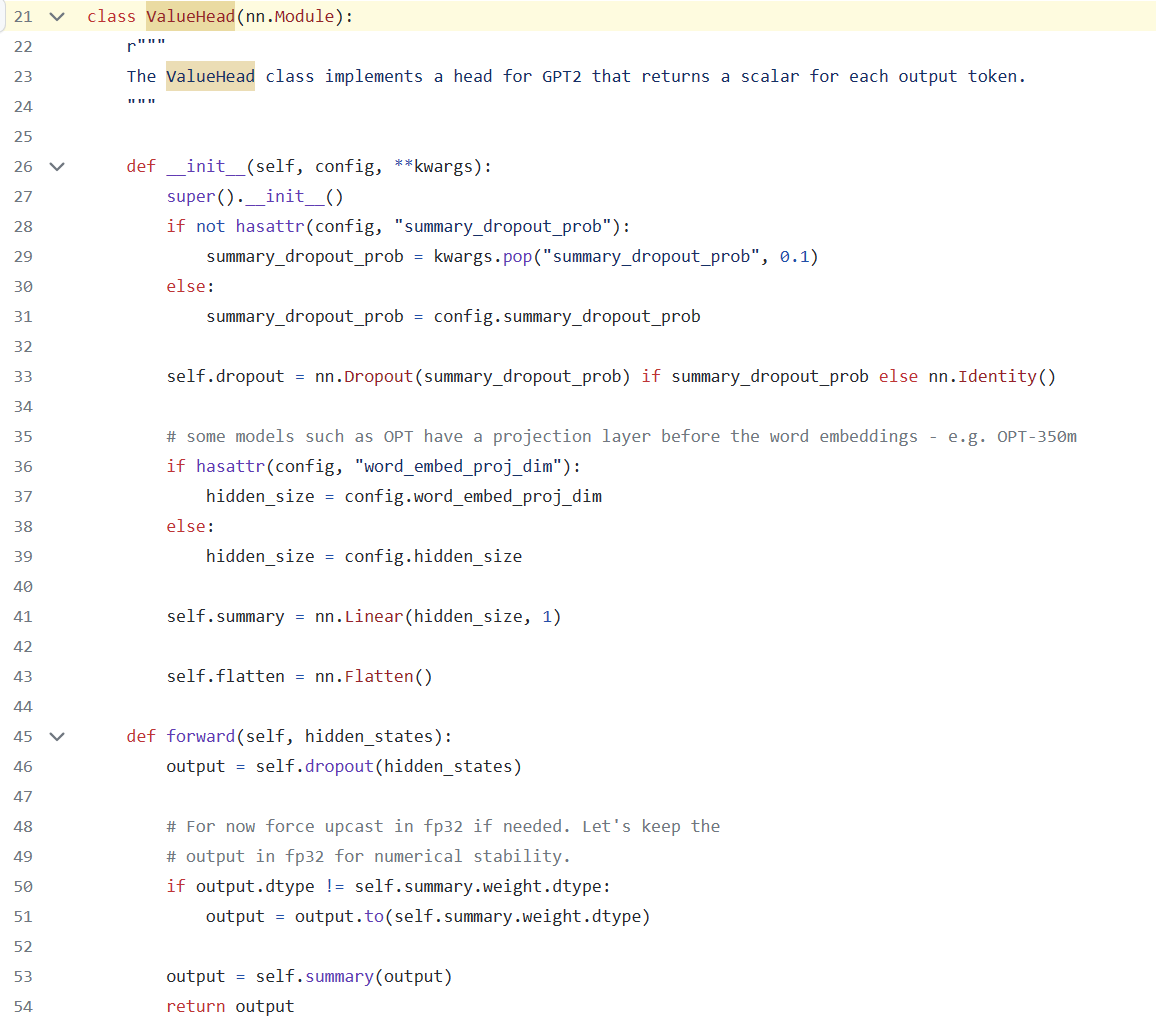
Value Head
The value head is shared with the policy model’s underlying parameters but swaps the top layer for a linear model.
trl/trl/models/modeling_value_head.py at v0.7.1 · huggingface/trl (github.com)
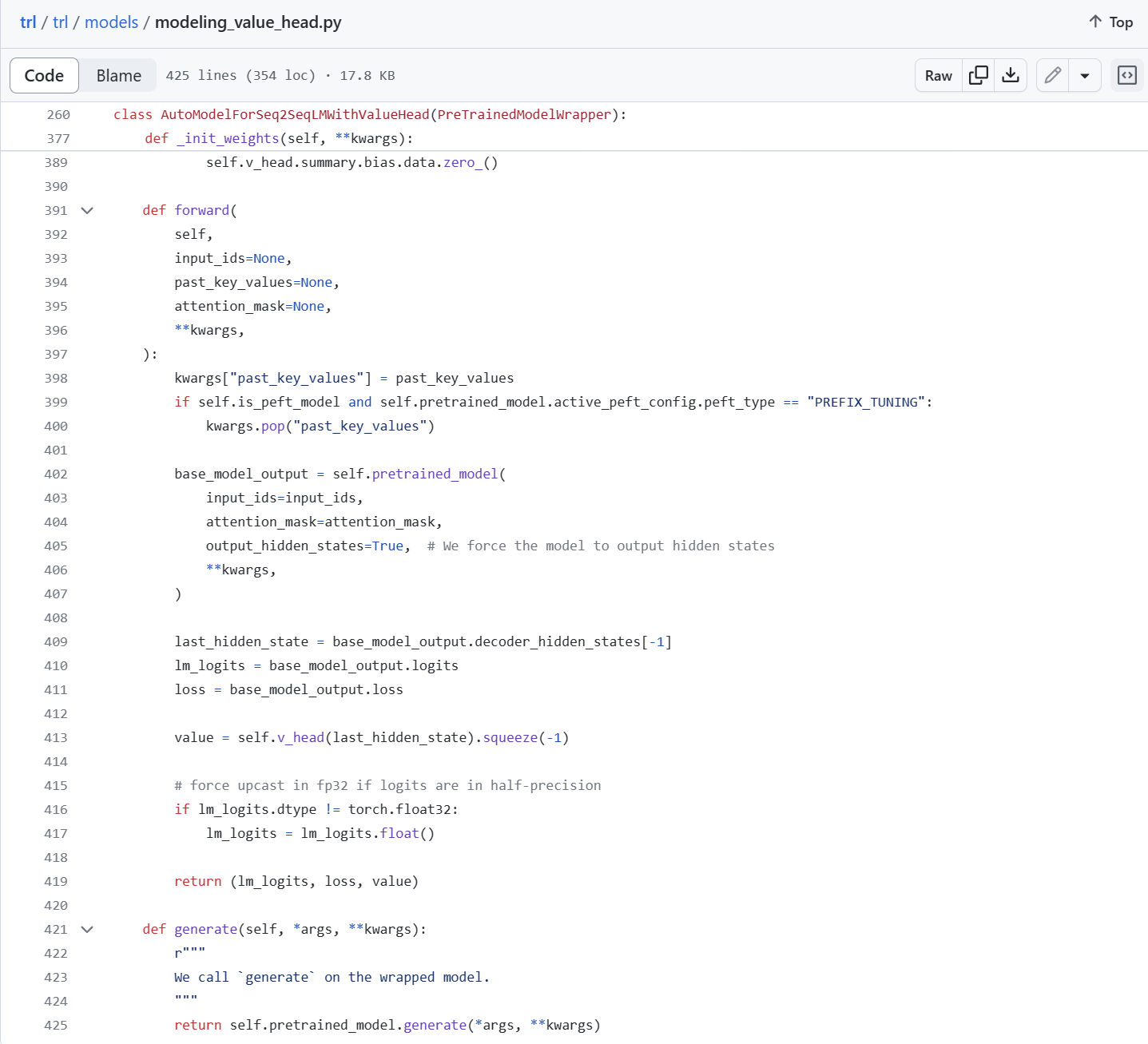
The self.v_head() function requires the last hidden state to predict the value.
Reward
The compute_reward() function is crucial for calculating the rewards based on the policy probabilities and SFT probabilities computed earlier.

The rewards are calculated for each token treated as an action, computing \(r−\beta×KL\), with \(r\) having a value only for the last token, as per design.
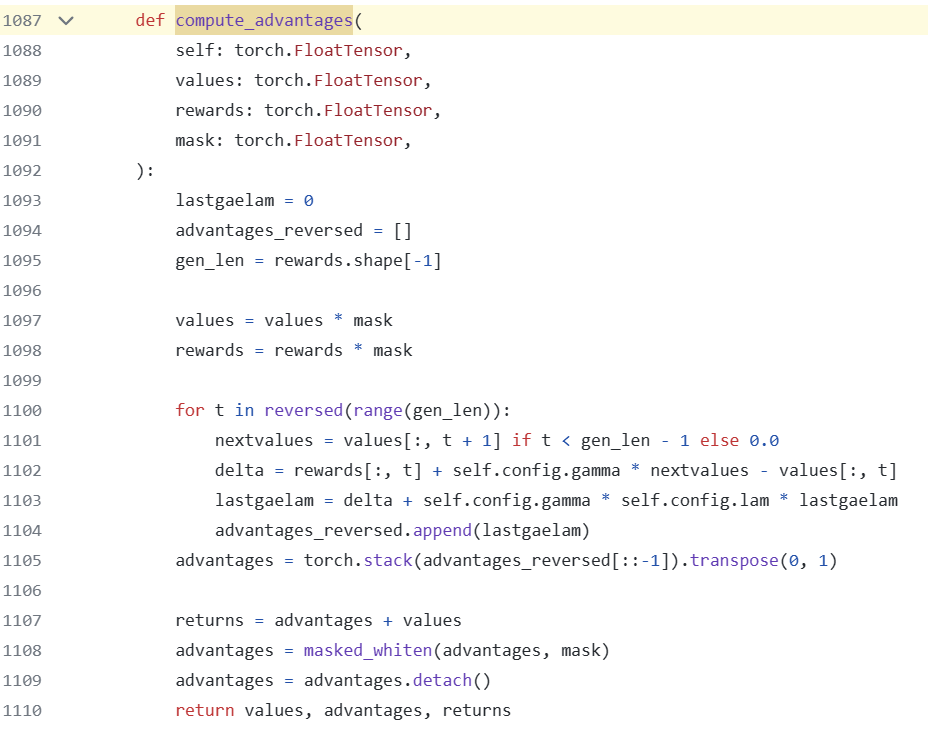
Advantage (GAE)
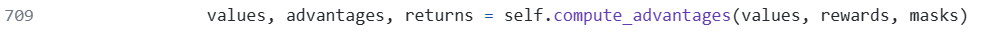
The Generalized Advantage Estimation (GAE) calculates values, advantages, and returns, incorporating a mask for calculation.
PPO Update
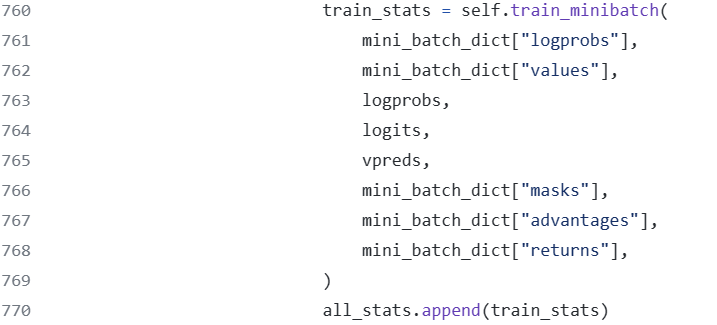
All data is stored as old outputs before iterating over minibatches for self.config.ppo_epochs epochs defined by self.config.ppo_epochs.


The minibatch dictionary mini_batch_dict calculates the information before the PPO update.

The training of minibatches combines the Policy and Value losses for joint updates.

The loss function is specially tailored, with the value loss being clipped and averaged over unmasked values, while the policy gradient loss remains standard.

This comprehensive overview explains how the step function integrates various components of the PPO algorithm, from calculating probabilities and values to updating the policy and value models based on computed rewards and advantages, ultimately refining the RL model’s behavior towards desired outcomes.