Publications
Selected publications and preprints. "*" denotes equal contribution.
-
 Unraveling Misinformation Propagation in LLM ReasoningIn Findings of EMNLP 2025, Long Paper , Nov 2025
Unraveling Misinformation Propagation in LLM ReasoningIn Findings of EMNLP 2025, Long Paper , Nov 2025Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning, positioning them as promising tools for supporting human problem-solving. However, what happens when their performance is affected by *misinformation*, i.e., incorrect inputs introduced by users due to oversights or gaps in knowledge? Such misinformation is prevalent in real-world interactions with LLMs, yet how it propagates within LLMs’ reasoning process remains underexplored. Focusing on mathematical reasoning, we present a comprehensive analysis of how misinformation affects intermediate reasoning steps and final answers. We also examine how effectively LLMs can correct misinformation when explicitly instructed to do so. Even with explicit instructions, LLMs succeed less than half the time in rectifyingmisinformation, despite possessing correct internal knowledge, leading to significant accuracy drops (10.02% – 72.20%), and the degradation holds with thinking models (4.30% – 19.97%). Further analysis shows that applying factual corrections early in the reasoning process most effectively reduces misinformation propagation, and fine-tuning on synthesized data with early-stage corrections significantly improves reasoning factuality. Our work offers a practical approach to mitigating misinformation propagation.
-
 Unveiling the Art of Heading Design: A Harmonious Blend of Summarization, Neology, and AlgorithmIn Findings of ACL 2024, Long Paper , Aug 2024
Unveiling the Art of Heading Design: A Harmonious Blend of Summarization, Neology, and AlgorithmIn Findings of ACL 2024, Long Paper , Aug 2024Crafting an appealing heading is crucial for attracting readers and marketing work or products. A popular way is to summarize the main idea with a refined description and a memorable acronym. However, there lacks a systematic study and a formal benchmark including datasets and metrics. Motivated by this absence, we introduce LOgogram, a novel benchmark comprising 6,653 paper abstracts with corresponding descriptions and acronyms. To measure the quality of heading generation, we propose a set of evaluation metrics from three aspects: summarization, neology, and algorithm. Additionally, we explore three strategies for heading generation(generation ordering, tokenization of acronyms, and framework design) under various prevalent learning paradigms(supervised fine-tuning, in-context learning with Large Language Models(LLMs), and reinforcement learning) on our benchmark. Our experimental results indicate the difficulty in identifying a practice that excels across all summarization, neologistic, and algorithmic aspects.
-
 Conditional Dichotomy Quantification via Geometric EmbeddingIn Proceedings of ACL 2025, Long Papers, Oral Paper ( 2.5% of all papers) , Jul 2025
Conditional Dichotomy Quantification via Geometric EmbeddingIn Proceedings of ACL 2025, Long Papers, Oral Paper ( 2.5% of all papers) , Jul 2025Conditional dichotomy, the contrast between two outputs conditioned on the same context, is vital for applications such as debate, defeasible inference, and causal reasoning. Existing methods that rely on semantic similarity often fail to capture the nuanced oppositional dynamics essential for these applications. Motivated by these limitations, we introduce a novel task, Conditional Dichotomy Quantification (ConDQ), which formalizes the direct measurement of conditional dichotomy and provides carefully constructed datasets covering debate, defeasible natural language inference, and causal reasoning scenarios. To address this task, we develop the Dichotomy-oriented Geometric Embedding (DoGE) framework, which leverages complex-valued embeddings and a dichotomous objective to model and quantify these oppositional relationships effectively. Extensive experiments validate the effectiveness and versatility of DoGE, demonstrating its potential in understanding and quantifying conditional dichotomy across diverse NLP applications. Our code and datasets are available at https://github.com/cui-shaobo/conditional-dichotomy-quantification.
-
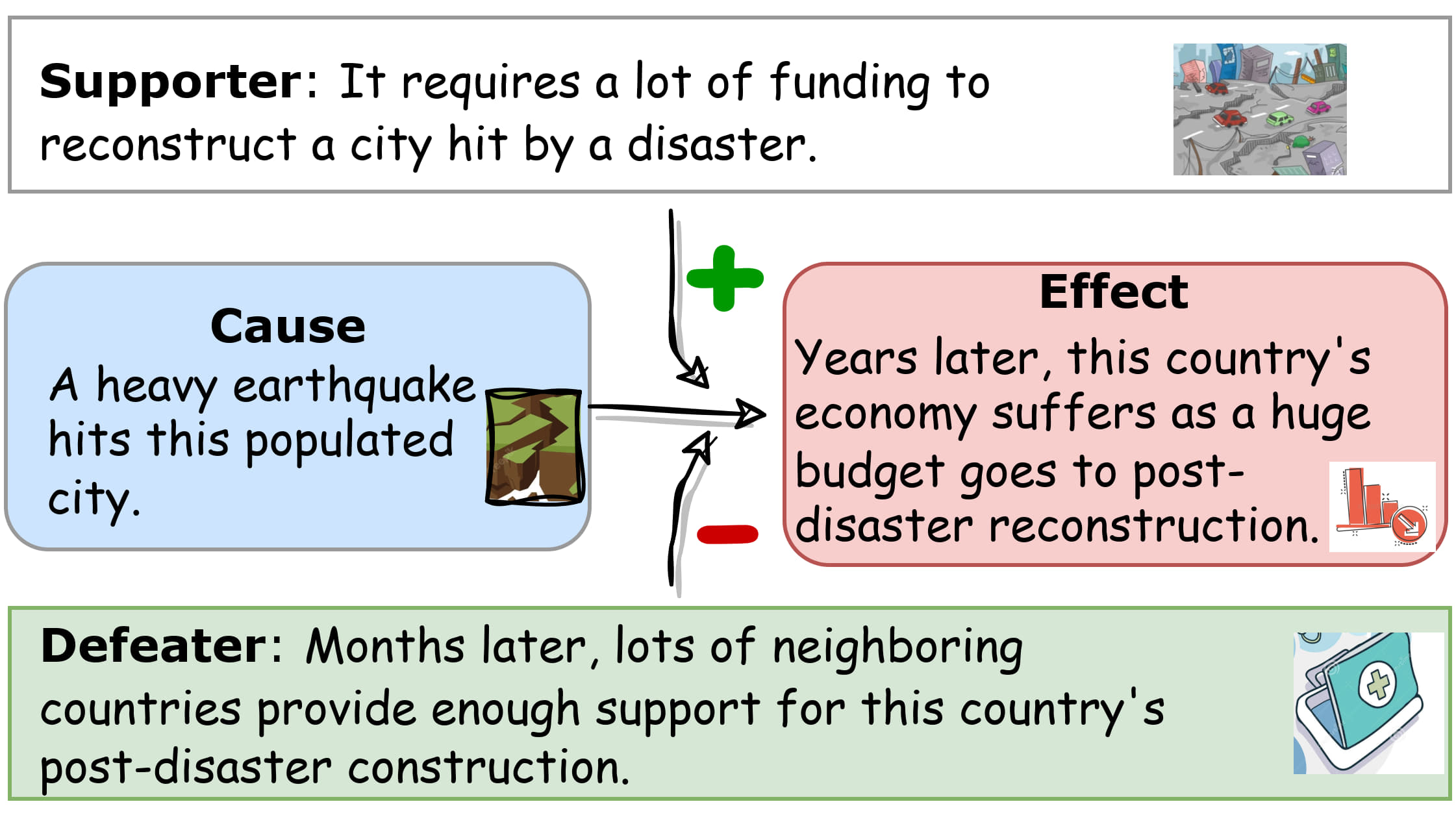 Exploring Defeasibility in Causal ReasoningShaobo Cui, Lazar Milikic, Yiyang Feng, Mete Ismayilzada, Debjit Paul, Antoine Bosselut, and Boi FaltingsIn Findings of ACL 2024, Long Paper , Aug 2024
Exploring Defeasibility in Causal ReasoningShaobo Cui, Lazar Milikic, Yiyang Feng, Mete Ismayilzada, Debjit Paul, Antoine Bosselut, and Boi FaltingsIn Findings of ACL 2024, Long Paper , Aug 2024Defeasibility in causal reasoning implies that the causal relationship between cause and effect can be strengthened or weakened. Namely, the causal strength between cause and effect should increase or decrease with the incorporation of strengthening arguments (supporters) or weakening arguments (defeaters), respectively. However, existing works ignore defeasibility in causal reasoning and fail to evaluate existing causal strength metrics in defeasible settings. In this work, we present δ-CAUSAL, the first benchmark dataset for studying defeasibility in causal reasoning. δ-CAUSAL includes around 11K events spanning ten domains, featuring defeasible causality pairs, namely, cause-effect pairs accompanied by supporters and defeaters. We further show that current causal strength metrics fail to reflect the change of causal strength with the incorporation of supporters or defeaters in δ-CAUSAL. To this end, we propose CESAR (Causal Embedding aSsociation with Attention Rating), a metric that measures causal strength based on token-level causal relationships. CESAR achieves a significant 69.7% relative improvement over existing metrics, increasing from 47.2% to 80.1% in capturing the causal strength change brought by supporters and defeaters. We further demonstrate even Large Language Models (LLMs) like GPT-3.5 still lag 4.5 and 10.7 points behind humans in generating supporters and defeaters, emphasizing the challenge posed by δ-CAUSAL.
-
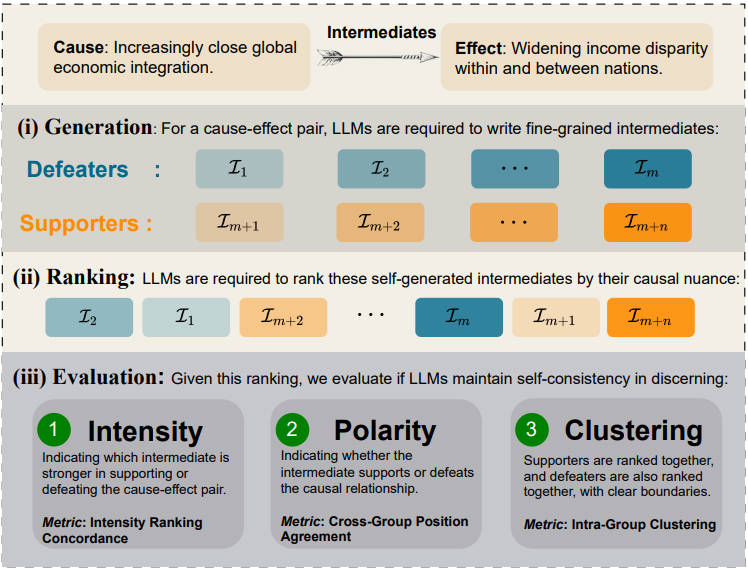 Nuance Matters: Probing Epistemic Consistency in Causal ReasoningProceedings of the AAAI 2025, Long Paper, Apr 2025
Nuance Matters: Probing Epistemic Consistency in Causal ReasoningProceedings of the AAAI 2025, Long Paper, Apr 2025Previous research on causal reasoning often overlooks the subtleties crucial to understanding causal reasoning. To address this gap, our study introduces the concept of causal epistemic consistency, which focuses on the self-consistency of Large Language Models (LLMs) in differentiating intermediates with nuanced differences in causal reasoning. We propose a suite of novel metrics – intensity ranking concordance, cross-group position agreement, and intra-group clustering – to evaluate LLMs on this front. Through extensive empirical studies on 21 high-profile LLMs, including GPT-4, Claude3, and LLaMA3-70B, we have favoring evidence that current models struggle to maintain epistemic consistency in identifying the polarity and intensity of intermediates in causal reasoning. Additionally, we explore the potential of using internal token probabilities as an auxiliary tool to maintain causal epistemic consistency. In summary, our study bridges a critical gap in AI research by investigating the self-consistency over fine-grained intermediates involved in causal reasoning.




